Lexer Usage
Instantiation
A lexer object instance is created by using the library’s make_lexer() factory function. It mimics the behaviour of function templates as found in languages (such as C++, C#, or Rust) and therefore needs two consecutive function calls for the following data:
Template parameters for setting a custom matcher and lexer implementation.
These can generally be ignored, and should only be used if the default implementations are not adequate. See also: Customizing Regex Engine.Generic initialization parameters supported by each lexer.
ruleset: lex2.RulesetType = [
# Identifier Regex pattern
lex2.Rule("WORD", r"[a-zA-Z]+"),
lex2.Rule("NUMBER", r"[0-9]+"),
lex2.Rule("PUNCTUATION", r"[.,:;!?\\-]")
]
options = lex2.LexerOptions()
options.space.returns = True
# Both optional, but best
# practice to set ruleset
# ┌───────┴────────┐
lexer: lex2.ILexer = lex2.make_lexer()(ruleset, options)
- lex2.make_lexer(MATCHER_T, LEXER_T)(ruleset=None, options=<lex2.LexerOptions object>)
Factory function for creating a lexer instance.
If no values are provided for the template parameters, the implementations used for the matcher and lexer will default to the library constants
DEFAULT_MATCHERandDEFAULT_LEXERrespectively.Template Parameters
- MATCHER_TType[BaseMatcher], optional
Template class type that implements the
BaseMatcherbase class.By default
DEFAULT_MATCHER- LEXER_TType[BaseLexer], optional
Template class type that implements the
BaseLexerbase class.By default
DEFAULT_LEXER
- Parameters
ruleset (RulesetType, optional) –
Initial ruleset.
By default
[]options (LexerOptions, optional) –
Struct specifying processing options of the lexer.
By default
LexerOptions()
- Return type
Textstream I/O
When a lexer is instantiated, it must first be given a stream of text data that it must process. For all lexers, this functionality is handled by the textio sub-package: the Textstream set of components handle the lower-level file/memory I/O management (i.e. reading contents into memory buffers exposed to the lexer), while the TextIO class and its corresponding interface ITextIO are exposed to the user for top-level I/O management (i.e. opening/loading/closing streams).
The UML class diagram below visualizes and summarizes the relationships between classes and interfaces just discussed.
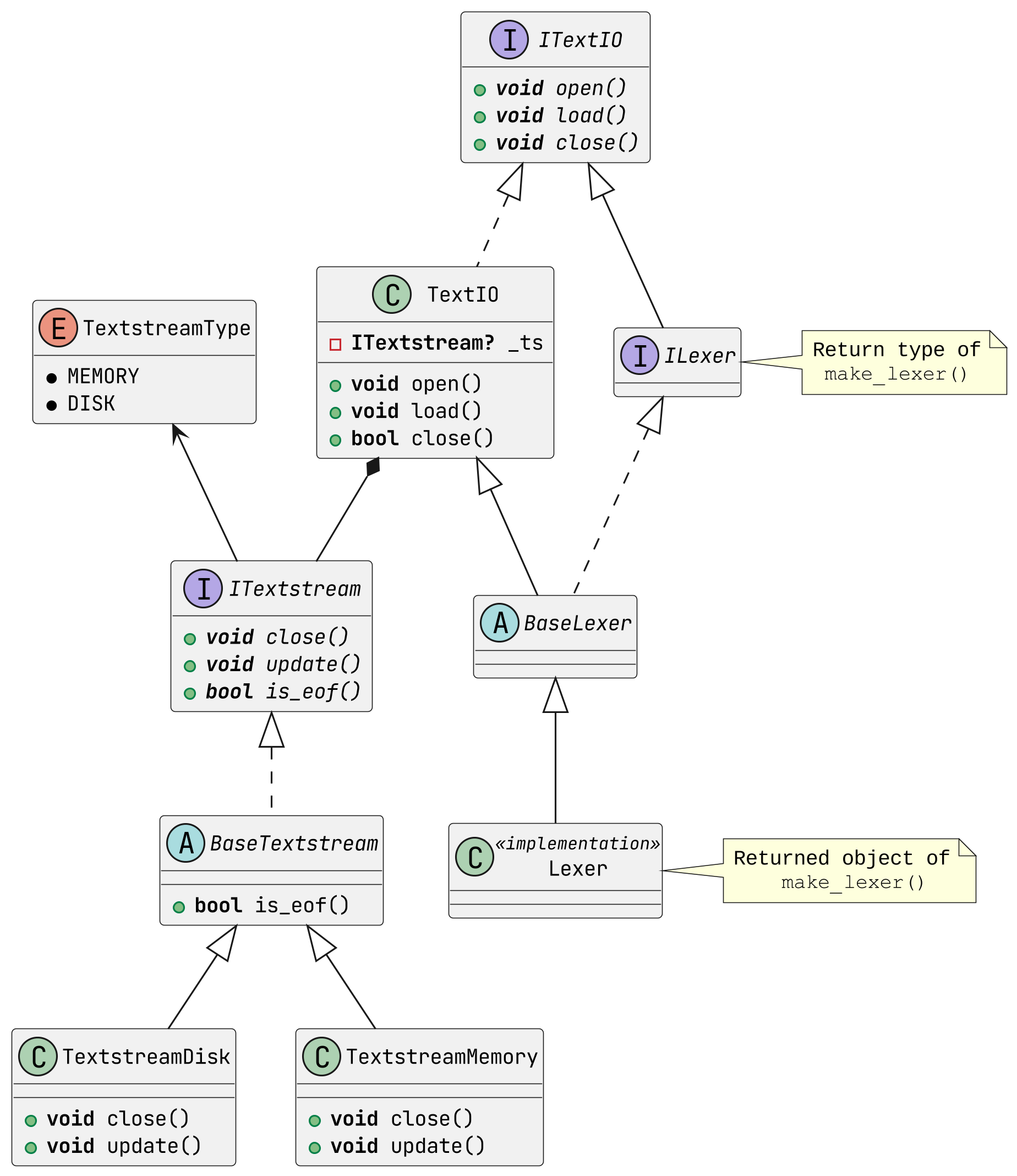
UML class diagram visualizing TextIO and Textstream inheritance
As discussed, the ITextIO interface is what is exposed to the user, which is part of each lexer because of the inherited interface. Through the interface, already instanced string objects can be passed directly using the load() method; files can be read either in chunks or one large buffer with the open() method; streams are closed manually using the close() method.
lexer: lex2.ILexer = lex2.make_lexer()()
lexer.open("/path/to/some/file.txt")
# Note that opening a new stream automatically closes the previous stream
lexer.load("Text data passed directly.")
lexer.close()
- class lex2.textio.ITextIO
Bases:
ABCInterface to a class implementing TextIO functionality.
- abstract open(fp, buffer_size=512, encoding='UTF-8', convert_line_endings=True)
Opens a textfile.
- Parameters
fp (str | Path) – String or Path object of a text file to open.
buffer_size (int, optional) – Size of the buffer in kilobytes (kB). A size of zero (0) allocates the whole file into memory. In order to completely capture a token, its length must be smaller or equal to half the buffer size value. Note that the buffer size will be floored to the nearest even number.
encoding (str, optional) – Encoding of the text file.
convert_line_endings (bool, optional) – Convert line-endings from Windows style to UNIX style.
- abstract load(str_data, convert_line_endings=False)
Load string data directly.
- Parameters
str_data (str) – String data to directly load. Note that encoding depends on the system-wide encoding.
convert_line_endings (bool, optional) – Convert line-endings from Windows style to UNIX style.
- abstract close()
Closes and deletes textstream resources.
Iteration and Tokenization
Once a lexer is instantiated and prepared, the lexer’s get_next_token() method is to be used to tokenize the input data. Whenever the method is called, the lexer will iterate through the textstream and return the next identifiable token it can find back to the caller. Once the end of stream (EOF) is reached, the lexer will raise the EOF signal exception to let the caller know to break out of a main lexing loop.
Tokens are in the form of Token class instances, and contain information about the token type, tokenized data, and position in the textstream (in the form of a TextPosition class instance).
ruleset: lex2.RulesetType = [
lex2.Rule("WORD", r"[a-zA-Z]+"),
lex2.Rule("PUNCTUATION", r"[.,:;!?\\-]")
]
lexer: lex2.ILexer = lex2.make_lexer()(ruleset)
lexer.load("Some input data.")
# Main loop
token: lex2.Token
while (1):
# Tries to find the next token in the textstream.
# A try/catch block is required at the same or
# higher level to catch the 'EOF' exception signal
# whenever the textstream is exhausted of data.
# ┌────────────────┴────────────────┐
try: token = lexer.get_next_token()
except lex2.excs.EOF:
break
info = [
f"ln: {token.pos.ln +1}",
f"col: {token.pos.col+1}",
token.id,
token.data,
]
print("{: <8} {: <12} {: <15} {: <10}".format(*info))
lexer.close()
>>> ln: 1 col: 1 WORD Some
>>> ln: 1 col: 6 WORD input
>>> ln: 1 col: 12 WORD data
>>> ln: 1 col: 16 PUNCTUATION .
- class lex2.Token
Represents a token that is output during lexical analysis.
- __init__(id='', data='', pos=<lex2.textio._textposition.TextPosition object>, groups=())
Token object instance initializer.
- Parameters
id (str, optional) –
The identifying string of the resulting token’s type (e.g. “NUMBER”, “WORD”).
By default
""data (str, optional) –
String data of the identified token.
By default
""position (TextPosition, optional) –
Position in the textstream where the token occurs.
By default
TextPosition()groups (Iterable[str], optional) –
Result of regex match, split by encapsulated groups.
By default
()
- id: str
The identifier of a token’s type (e.g. “NUMBER”, “WORD”).
- data: str
Result of regex match.
- pos: TextPosition
Position in the textstream where a token occurs.
- groups: Sequence[str]
Result of regex match, split by encapsulated groups.
- is_rule(expected_rule)
Evaluates if the token’s identifier matches that of a given rule.
- Parameters
expected_rule (Rule) – Rule object instance.
- Return type
bool
- is_rule_oneof(expected_rules)
Evaluates if the token’s identifier matches that one of a given list of rules.
- Parameters
expected_rules (List[Rule]) – List of Rule object instances.
- Return type
bool
- validate_rule(expected_rule)
Validates that the token’s identifier matches that of a given rule.
- Parameters
expected_rule (Rule) – Rule object instance.
- Raises
UnknownTokenError – When the token’s identifier does not match that of a given rule.
- validate_rule_oneof(expected_rules)
Validates that the token’s identifier matches that one of a given list of rules.
- Parameters
expected_rules (List[Rule]) – List of Rule object instances.
- Raises
UnknownTokenError – When the token’s identifier does not match that of a given rule.
- class lex2.textio.TextPosition
Struct that holds data about the position in a textstream.
- __init__(pos=0, col=0, ln=0)
TextPosition object instance initializer.
- Parameters
pos (int, optional) – Absolute position in a text file. Note that multi-byte characters are counted as one position.
col (int, optional) – Column at a position in a text file. Counting starts from 0.
ln (int, optional) – Line at a position in a text file. Counting starts from 0.
- pos: int
Absolute position in a textstream. Counting starts from 0. Note that multi-byte characters are counted as one position.
- col: int
Column of a position in a textstream. Counting starts from 0.
- ln: int
Line of a position in a textstream. Counting starts from 0.
Token Validation
For the use-case of making a parser and creating abstract trees (AST), the token class includes the is_rule() / is_rule_oneof() and validate_rule_oneof() / validate_rule() methods for checking and validating if a token matches an expected rule, by means of passing Rule object instances.
class rules:
word = lex2.Rule("WORD", r"[a-zA-Z]+")
punc = lex2.Rule("PUNCTUATION", r"[.,:;!?\\-]")
ruleset = [word, punc]
lexer: lex2.ILexer = lex2.make_lexer()(rules.ruleset)
lexer.load("word")
token: lex2.Token = lexer.get_next_token()
token.validate_rule(rules.word)
token.validate_rule(rules.punc)
>>> lex2.excs.UnexpectedTokenError: Unexpected token type "WORD" @ ln:1|col:1
>>> Expected the following type(s): "PUNCTUATION", for the following data:
>>> "word"