Customizing Regex Engine
In the event that the regex engine used by default (from Python’s builtin re module) is inadequate, it is possible to substitute it for a regex engine of the user’s own choice.
Underlying Architecture
While not essential, it may be beneficial to understand the way how the library utilizes a regex engine to match tokens. Each Rule stores a matcher-like object that implements the BaseMatcher abstract class (and thus the IMatcher interface). A matcher is responsible for carrying out the matching behaviour to try and identify text according to the regex pattern stored in the rule.
When a ruleset is assigned to a lexer, it will immediately check if each rule’s matcher attribute is set accordingly, and will otherwise instantiate an appropriate matcher implementation. Also, if a matcher has not yet compiled the corresponding regex pattern, the lexer will automatically call the compile_pattern() method to do so.
When the lexer iterates over rules, it will access each rule’s matcher and call the match() method. This will a boolean to indicate whether a match was found. A lexer passes down its textstream to match() to be used as input data for the compiled regex pattern, and passes down an instance of Token for the matcher to store the match data in.
The UML class diagram below visualizes and summarizes the relationships between classes and interfaces just discussed.
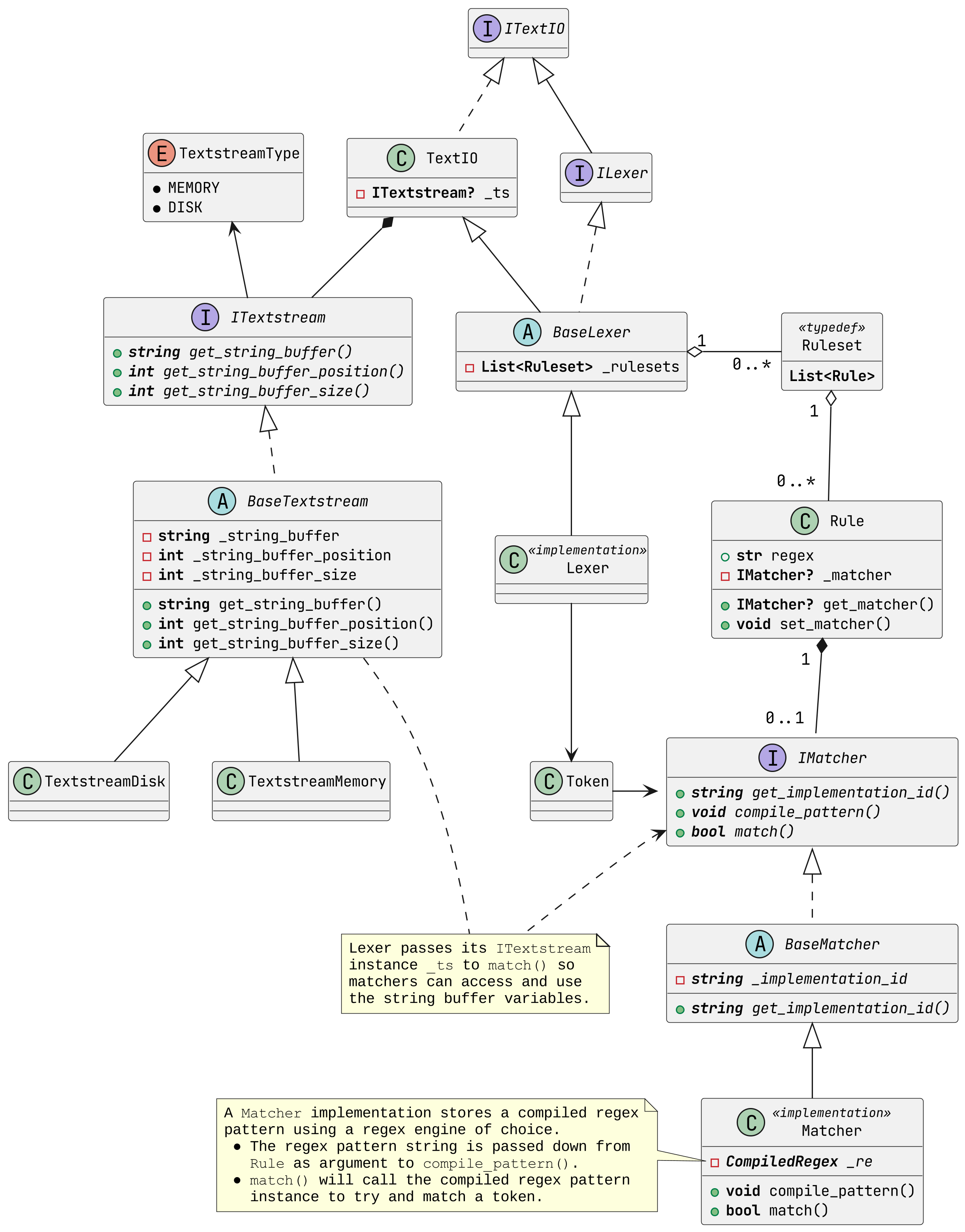
UML class diagram visualizing the textstream-lexer-rule-matcher relationships
Practical Example
To explain how to define and use a custom matcher, it’s best illustrated using a practical example. For this example, the regex engine from the library ‘regex’ by Matthew Barnett is used.
There’s a few components:
All matcher classes must inherit from the
BaseMatcherabstract base class.The base class constructor must be called.
Implementation of the
compile_pattern()method.A regex pattern string is given as input for generating a compiled regex pattern.
The compiled regex pattern needs to be stored as a class instance attribute, or via a reference to another object.
Implementation of the
match()method.The lexer’s textstream is passed down to use as input for the compiled regex pattern. It is an instance of
ITextstream.
Also see Improving match() Performance on Python.A token is passed down to store the match data. It is an instance of
Token.If a match is found, store the the string value of the match in
token.dataand the encapsulated groups intoken.groups, and returnTrue. If no match is found, returnFalse.
import lex2
import regex as rgx
class CustomMatcher (lex2.matcher.BaseMatcher):
_pattern : rgx.Pattern
def __init__(self) -> None:
super().__init__()
def compile_pattern(self, regex: str) -> None:
self._pattern = rgx.compile(regex)
def match(self, ts: lex2.textio.ITextstream, token: lex2.Token) -> bool:
regex_match = self._pattern.match(
ts.get_string_buffer(), # Data
ts.get_string_buffer_pos(), # Data position start
ts.get_string_buffer_size(), # Data position end
)
if (regex_match):
token.data = regex_match.group()
token.groups = regex_match.groups()
return True
return False
To use your custom defined matcher, you need to pass it as a template argument to the make_lexer() function as follows:
lexer: lex2.ILexer = lex2.make_lexer(MATCHER_T=CustomMatcher)(ruleset, options)
Improving match() Performance on Python
Because Python has to constantly do dictionary lookups, accessing the string buffer variables through the interface methods may cause noticeable slowdown on larger lexing operations. Hence you can skip the methods and reference the private variables directly, as shown below.
def match(self, ts: lex2.textio.ITextstream, token: lex2.Token) -> bool:
regex_match = self._pattern.match(
ts._string_buffer, # Data
ts._string_buffer_pos, # Data position start
ts._string_buffer_size, # Data position end
)
...